# 邮件预处理节点 defread_email(state: EmailState): """Alfred reads and logs the incoming email""" email = state["email"]
# 在这里我们可能会做一些初步的预处理 print(f"Alfred is processing an email from {email['sender']} with subject: {email['subject']}")
# 这里不需要更改状态 return {}
# 邮件分类节点 defclassify_email(state: EmailState): """Alfred uses an LLM to determine if the email is spam or legitimate""" email = state["email"]
# 为 LLM 准备提示 prompt = f""" As Alfred the butler, analyze this email and determine if it is spam or legitimate. Email: From: {email['sender']} Subject: {email['subject']} Body: {email['body']} First, determine if this email is spam. If it is spam, explain why. If it is legitimate, categorize it (inquiry, complaint, thank you, etc.). """
# Call the LLM messages = [HumanMessage(content=prompt)] response = model.invoke(messages)
# 处理垃圾邮件节点 defhandle_spam(state: EmailState): """Alfred discards spam email with a note""" print(f"Alfred has marked the email as spam. Reason: {state['spam_reason']}") print("The email has been moved to the spam folder.")
# 我们已处理完这封电子邮件 return {}
# 对正常邮件起草答复的节点 defdraft_response(state: EmailState): """Alfred drafts a preliminary response for legitimate emails""" email = state["email"] category = state["email_category"] or"general"
# 为 LLM 准备提示词 prompt = f""" As Alfred the butler, draft a polite preliminary response to this email. Email: From: {email['sender']} Subject: {email['subject']} Body: {email['body']} This email has been categorized as: {category} Draft a brief, professional response that Mr. Hugg can review and personalize before sending. """
# Call the LLM messages = [HumanMessage(content=prompt)] response = model.invoke(messages)
# 提醒用户收到邮件的节点 defnotify_mr_hugg(state: EmailState): """Alfred notifies Mr. Hugg about the email and presents the draft response""" email = state["email"]
print("\n" + "=" * 50) print(f"Sir, you've received an email from {email['sender']}.") print(f"Subject: {email['subject']}") print(f"Category: {state['email_category']}") print("\nI've prepared a draft response for your review:") print("-" * 50) print(state["draft_response"]) print("=" * 50 + "\n")
# 垃圾邮件示例 email = { "sender": "winner@lottery-intl.com", "subject": "YOU HAVE WON $5,000,000!!!", "body": "CONGRATULATIONS! You have been selected as the winner of our international lottery! To claim your $5,000,000 prize, please send us your bank details and a processing fee of $100." }
Alfred is processing an email from winner@lottery-intl.com with subject: YOU HAVE WON $5,000,000!!! Alfred has marked the email as spam. Reason: the sender uses a suspicious, generic domain (lottery-intl.com) not associated with any legitimate international lottery; the subject line employs excessive punctuation and all-caps urgency ("you have won $5,000,000!!!"); the body contains hallmark scam indicators—unsolicited notification of a large monetary prize, demand for sensitive personal information (bank details), and a request for an upfront "processing fee" (a classic advance-fee fraud tactic); and no legitimate lottery notifies winners via unsolicited email or requires payment to claim a prize. The email has been moved to the spam folder.
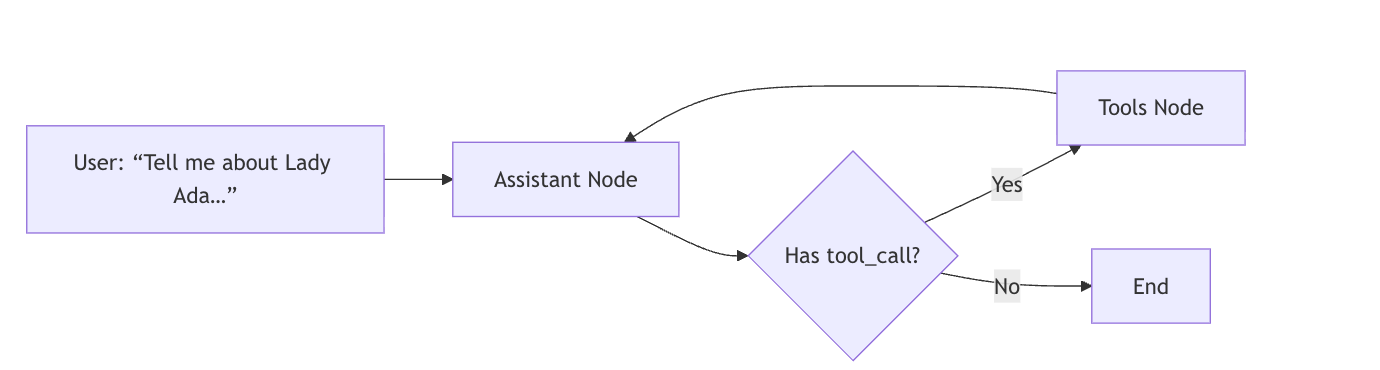
import datasets from langchain_core.documents import Document from langchain_community.retrievers import BM25Retriever from langchain_core.tools import Tool from langchain_openai import ChatOpenAI from typing import TypedDict, Annotated from langgraph.graph.message import add_messages from langchain_core.messages import AnyMessage, HumanMessage, AIMessage from langgraph.prebuilt import ToolNode from langgraph.graph import START, StateGraph from langgraph.prebuilt import tools_condition
defextract_text(query: str) -> str: """Retrieves detailed information about gala guests based on their name or relation.""" results = bm25_retriever.invoke(query) if results: return"\n\n".join([doc.page_content for doc in results[:3]]) else: return"No matching guest information found."
guest_info_tool = Tool( name="guest_info_retriever", func=extract_text, description="Retrieves detailed information about gala guests based on their name or relation." )
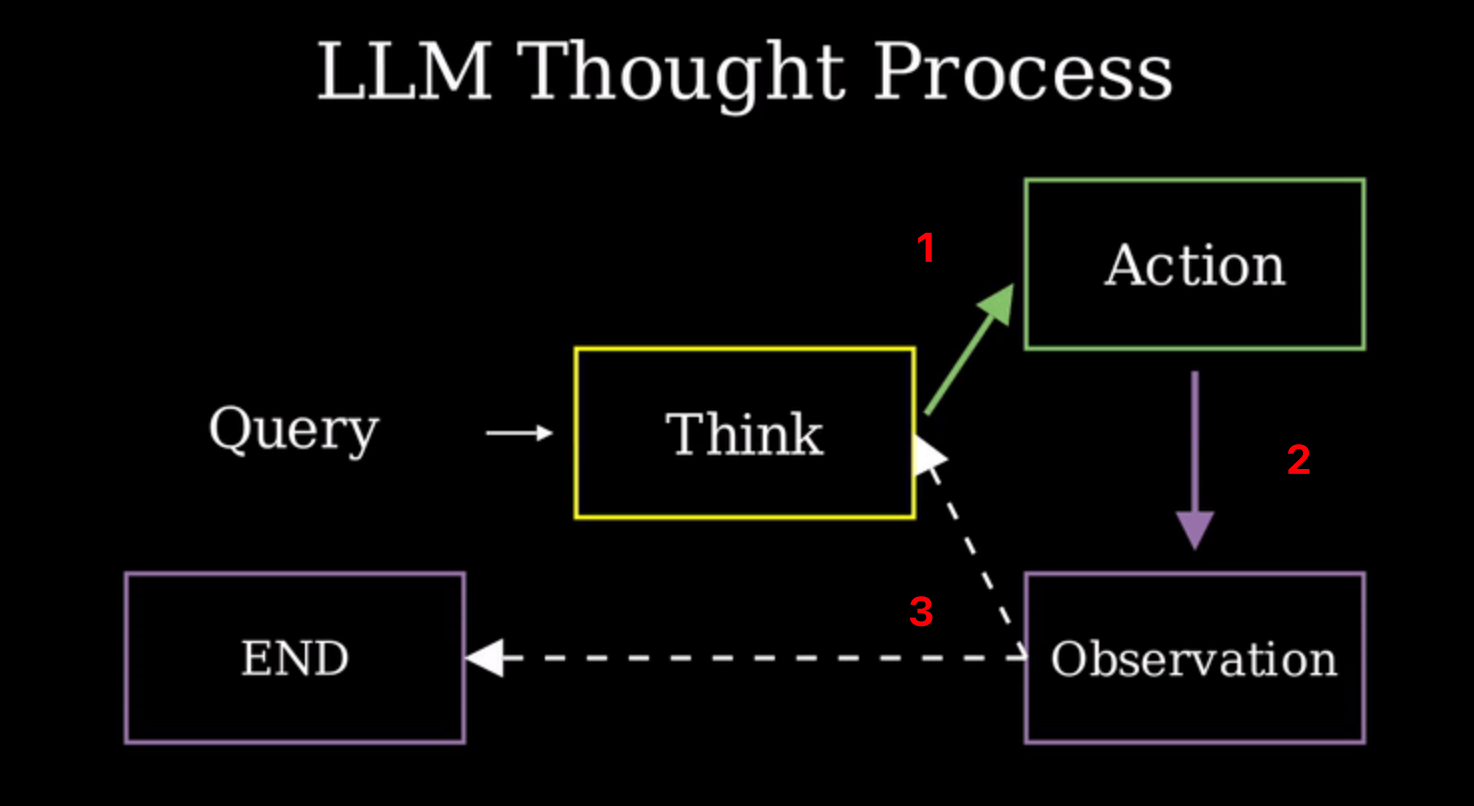
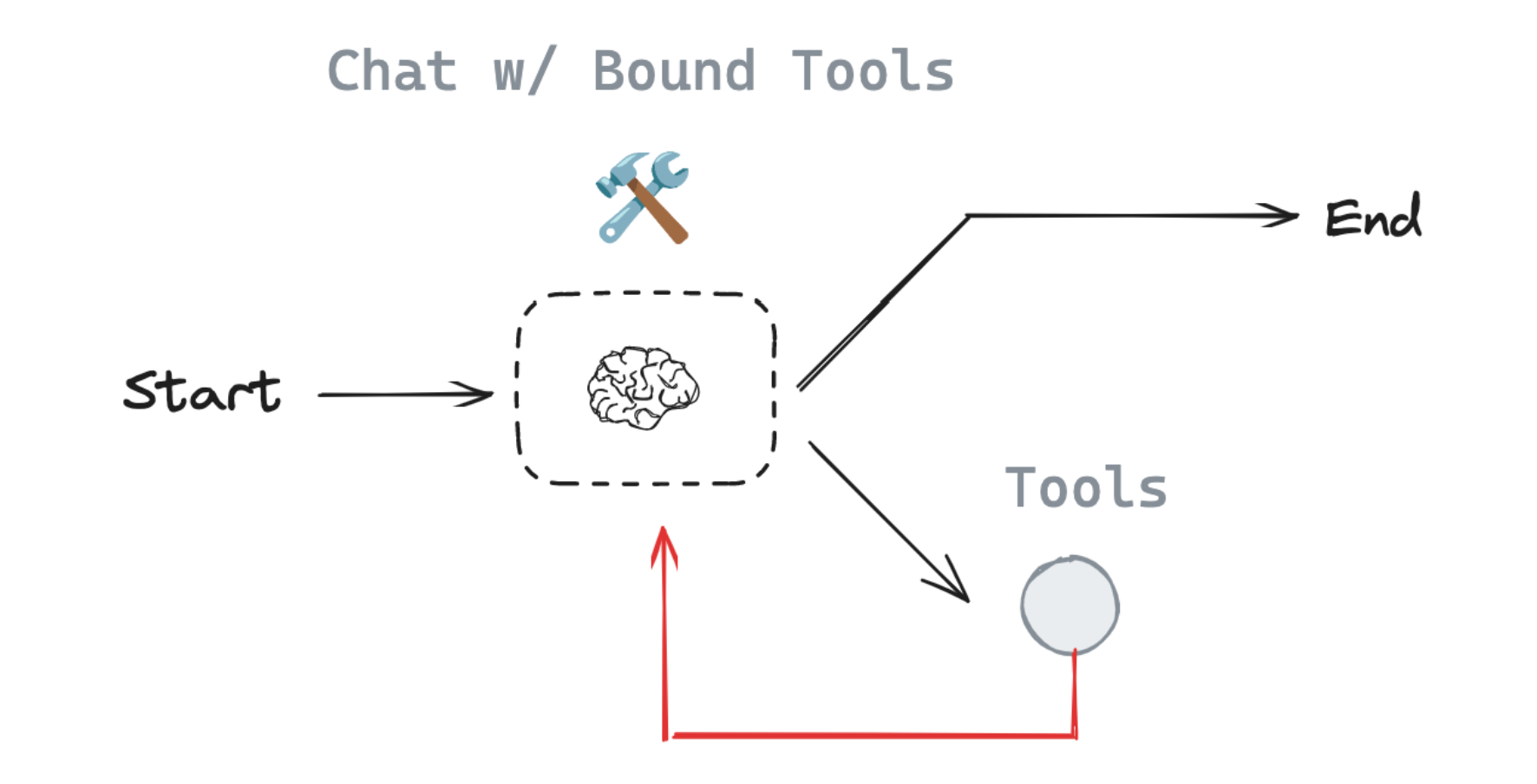
# 定义边 edges builder.add_edge(START, "assistant") builder.add_conditional_edges( "assistant", # If the latest message requires a tool, route to tools # Otherwise, provide a direct response tools_condition, ) builder.add_edge("tools", "assistant") agent = builder.compile()
############################################################################## # 测试输出 messages = [HumanMessage(content="Tell me about our guest named 'Lady Ada Lovelace'.")] response = agent.invoke({"messages": messages})
Agent's Response: Lady Ada Lovelace is your best friend and an esteemed mathematician, renowned for her pioneering work in computing. She is often celebrated as the first computer programmer due to her contributions to Charles Babbage's Analytical Engine. Her visionary insights into mathematics and technology have left a lasting legacy. You can reach her at ada.lovelace@example.com.